爬虫学习笔记(三)
概要:在这篇记录中,我们将学习用后缀为.py的文件记录Python代码、Python的I/O、计算机中的编码和字符集等等内容。
.py后缀文件
咱们都知道js文件的后缀是.js,Python文件的的后缀是什么呢?
和.js文件类似,我们可以将代码写入.py文件中,然后通过Python解释器去执行。在安装了上一篇文章中我推荐的插件后,我们只需右键选择Run Python然后选择第一项即可直接运行该文件,选择Format Document还能格式化代码。
I/O
任何计算机程序都是为了执行一个特定的任务,有了输入,用户才能告诉计算机程序所需的信息,有了输出,程序运行后才能告诉用户任务的结果。输入是Input,输出是Output,因此,我们把输入输出统称为Input/Output,或者简写为IO。
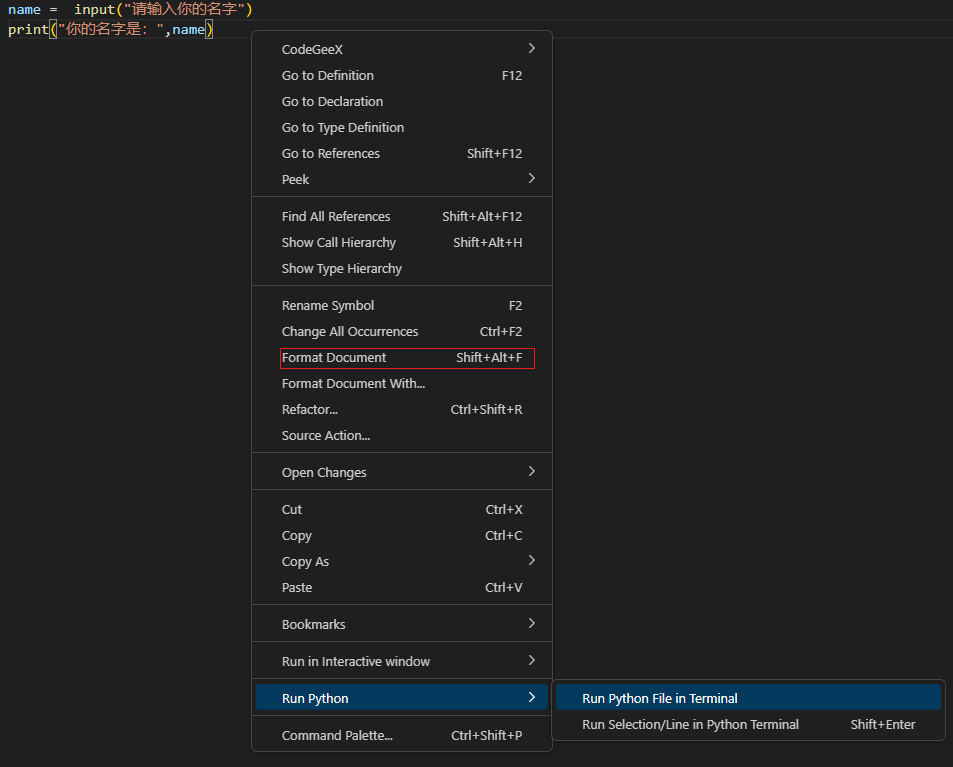
input()和print()是在命令行下面最基本的输入和输出。我们可以用一个变量记录用户的输出,就像上图一样:name=input("请输入你的名字"),还可以给用户提示文本。
基础
因为笔者是主学的JavaScript,所以在记录基础知识时,会不受控制的和JavaScript进行对比,这样可以加深对两个语言的理解程度,希望你们喜欢:
- 和js的//代表注释不同,python使用#当注释
- js大部分时候使用的是{}来表示代码块,而python使用缩进来表示,我们约定俗成的使用4个空格的缩进
- python也是大小写敏感
- Python允许在数字中间以
_分隔 - 和js一样可以在字符串中使用转义字符
\来标识特殊的字符,比如双引号中展示双引号,比如换行\n - 用
\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容 - 在Python中,可以直接用
True、False表示布尔值(请注意大小写),布尔值可以用and、or和not运算,这就和js中的&&、||、!的一样 - Python 中的按位运算符与 JavaScript 中的一样,包括按位与
&、按位或|、按位异或^、按位取反~,以及左移<<和右移>>运算符。 - 空值是Python里一个特殊的值,用
None表示 - 变量名必须是大小写英文、数字和
_的组合,且不能用数字开头 - 和js一样变量名必须是大小写英文、数字和
_的组合,且不能用数字开头,但不用像js一样需要用var、let、const进行声明,如果想表示常量的话,用全部大写的变量名表示常量,当然它本质还是变量 - 和js一样,python也是
动态语言,与之对应的是静态语言,静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错,而动态语言则不需要指定类型。 - 虽然js和python
/都表示除,但是python无论结果是不是整数,都会返回浮点数,如1/1 => 1.0,要想返回整数的话可以使用地板除//,只取结果的整数部分。余数运算和js一样是% - 注意Python的整数没有大小限制,Python的浮点数也没有大小限制,但是超出一定范围就直接表示为
inf(无限大)
留一个问题,python中的and运算符和or运算符有和js中&&和||的短路效果吗?
编码和字符集
老生常谈的话题了,计算机是看不懂字符串的,只能处理数字,要想让它可以处理字符串,我们需要给他一个映射表,规定这个字符对应的二进制是多少,规定A对应的二进制为01000001,这样计算机就知道该如何处理A了。
一个字节是8位,有256种组合,然后第一个编码表将大小写英文字母、数字和一些符号等127个字符给记录进去了,也就是ASCII编码表。但是那么多国家都有各自的语言,只靠这ASCII肯定是不够的,于是我国出了GB2312编码,日本出了Shift_JIS编码,就导致在多语言混合的文本中,显示出来会有乱码。
因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,形成一个统一的标准。Unicode字符集只是标准并不是实现,它的实现有UTF-8、UTF-16、UTF-32等,它们使用不同的字节序列来表示Unicode字符集中的字符,但最常用的是UCS-16编码,用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
UTF-16是用两个字节表示一个字符,在全英文的情况下,只是比ASCII多补8个0而已,这很不划算,所以又出现了可变长度的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。大大滴节省空间。
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
- 在许多编程语言和操作系统中,字符串通常使用Unicode编码来表示字符。当程序在内存中操作字符串时,会将字符按照Unicode编码的方式存储在内存中。
- UTF-8是一种针对Unicode设计的变长编码方案,在存储到硬盘或进行传输时常常会将Unicode字符转换为UTF-8编码。
- 当使用记事本或其他文本编辑器打开一个文件时,编辑器会将文件中的字节流按照指定的编码方式(例如UTF-8)解析为Unicode字符,然后在内存中进行编辑操作。编辑完成后,编辑器会将内存中的Unicode字符再次编码为指定的编码方式(例如UTF-8)并写回到文件中。
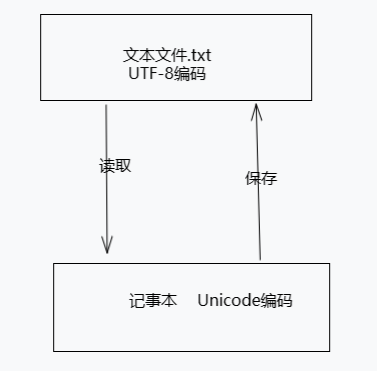
在浏览网页时,服务器会把以UTF-8编码(大部情况)进行存储的index.html以及其他文件传输给浏览器,浏览器接收到服务器传输的内容后,会根据HTTP响应头中指定的字符集编码来解析内容,如:Content-Type: text/html; charset=UTF-8。对于动态生成的内容为如下步骤:
- 服务器生成内容的编码:当服务器生成动态内容时,通常会以Unicode编码形式来表示字符,无论是从数据库、文件还是其他数据源中获取数据,都会以Unicode编码形式处理。
- 传输到浏览器的编码:在将动态生成的内容传输到浏览器时,服务器会根据HTTP响应的头部信息(如
Content-Type)指定字符集编码。如果字符集编码设置为UTF-8,那么服务器会将Unicode内容转换为UTF-8编码,并将带有UTF-8编码的内容传输给浏览器。 - 浏览器接收和解析内容:浏览器接收到服务器传输的内容后,会根据HTTP响应头中指定的字符集编码来解析内容。如果字符集编码为UTF-8,浏览器会将接收到的UTF-8编码的内容解码为Unicode字符,并在页面中渲染显示。
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python中的字符串
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言的。Python不同于js,js是中的字符串(String)类型是基于Unicode字符的,而Python除了基于Unicode的字符串,还有一种特殊的字符串-字节字符串(bytes string)。也就是在字符串前面加上b的字符串,来看看它们的的区别和相同点吧:
1 | x = b"ABC" |
- 编码方式:
- 字节字符串(bytes)是以字节的形式存储数据,不涉及字符编码。
- 字符串(str)是以Unicode字符的形式存储数据,需要使用字符编码(如UTF-8)来进行存储和解码。
- 不可变性:
- 字节字符串(bytes)是不可变的,一旦创建就无法修改。
- 字符串(str)也是不可变的,一旦创建就无法修改。
- 适用场景:
- 字节字符串(bytes)通常用于处理二进制数据,如图像、音频、网络数据等。
- 字符串(str)则用于处理文本数据,如文档、配置文件、用户输入等。
- 字面值表示:
- 字节字符串(bytes)使用
b"..."的形式表示,其中...是字节数据的字面值。 - 字符串(str)使用
"..."或'...'的形式表示,其中...是文本数据的字面值。
- 字节字符串(bytes)使用
字节字符串是一种特殊类型的字符串,它以字节的形式存储数据,而不是Unicode字符。这意味着字节字符串中的每个字符都由一个字节表示,而不是多个字节。所以中文是不能直接作为字节字符串的哦,会报错并提示你,字节字符串文字中不允许使用非 ASCII 字符。注意这里说的是直接使用,因为 Python 解释器无法确定如何编码这些字符。如果想要在字节字符串中包含非 ASCII 字符,可以使用转义序列或者将字符串编码为字节序列的方式来处理。
相关方法:
encode() 指定编码格式编码字符串
1 | '中文'.encode('utf-8') |
decode() 指定编码格式解码字符串
1 | str = "this is string example....wow!!!"; |
更多字符串方法可以参考官网、Python 字符串 | 菜鸟教程 。
疑问解答
1.计算机中内存、进程、线程各是什么?
先说结论:内存是临时存储程序及其数据的地方,进程是操作系统中的一个执行实例,操作系统通过进程管理来确保多个程序能够并发执行,并且有效地利用计算机资源。而线程则是进程中的执行单元,它们共同协作以实现程序的运行。
- 内存(RAM): 内存是计算机用于临时存储数据和程序的地方。它是一种易失性存储设备,这意味着当计算机关闭或断电时,存储在内存中的数据都会丢失。内存的主要目的是为了提供对数据的快速访问,因此相比于硬盘等存储设备,内存的读写速度要快得多。
- 进程: 进程是操作系统中的一个执行实例。当你启动一个程序时,操作系统会创建一个相应的进程来运行该程序。每个进程都拥有独立的内存空间,包括代码、数据、堆栈等。进程之间通常是相互隔离的,一个进程的数据不会直接影响到另一个进程。每个进程都有自己的资源分配和管理,包括内存、文件句柄等。
- 线程: 线程是进程中的一个执行单元。一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间和文件句柄等。不同于进程,线程之间共享同一份内存空间,因此线程间的通信和数据共享更为方便。线程的创建和切换相对于进程来说开销较小,因此多线程编程常用于提高程序的并发性和性能。
在一个程序运行时,操作系统会为其创建一个进程,并在该进程内创建一个或多个线程,这些线程负责执行不同的任务。这些任务所需的数据会被加载到内存中,然后由对应的线程执行。当程序结束时,操作系统会释放进程及其所占用的内存空间,这些数据也会从内存中清除。
2.我在vscode中删除文件夹怎么有时候可以成功有时候不能呢?
猜测是因为文件句柄被持有而导致的,你尝试删除项目中的一个文件夹,但是该文件夹中的某些文件正在被VS Code或其他程序使用,操作系统会阻止你删除这个文件夹,因为文件句柄还在被持有,只有在关闭VS Code或其他使用文件句柄的程序后,文件句柄才会被释放,你才能成功删除文件夹。那什么又是文件句柄呢?请往下看。
文件句柄(File Handle)是操作系统用于跟踪文件的抽象概念。在计算机系统中,文件句柄是一种标识符或引用,用于表示打开的文件。当应用程序需要读取或写入文件时,它首先要求操作系统打开该文件,并获得一个文件句柄。这个文件句柄允许应用程序对文件进行操作,如读取、写入、关闭等。
文件句柄包含了有关文件的一些重要信息,比如文件位置、文件权限、缓冲区信息等。它是应用程序与操作系统之间的接口,使得应用程序可以通过文件句柄来访问和操作文件,而不必关心文件在物理存储设备上的具体位置和细节。
在操作系统中,每个进程都有一张文件句柄表(File Descriptor Table),用于跟踪该进程打开的所有文件。当进程打开一个文件时,操作系统会为该文件分配一个文件句柄,并将该文件句柄添加到进程的文件句柄表中。当文件不再需要时,进程可以通过关闭文件句柄来释放相关资源。
文件句柄的使用使得操作系统可以更有效地管理文件资源,并且提供了一种抽象的方式来处理文件操作,使得应用程序更易于编写和维护。
3.js中没有字节字符串,那有类似作用的替代品吗?
js虽然没有字节字符串,但是提供了TypedArray和ArrayBuffer这两种类型,可以用于处理字节数据,与字节字符串有一定的相似性。
- ArrayBuffer是一种特殊的对象,用于表示通用的、固定长度的原始二进制数据缓冲区。它是一种低级别的对象,不直接操作数据,而是通过TypedArray或DataView来访问和操作数据。ArrayBuffer通常用于创建和传递二进制数据缓冲区,而TypedArray用于对这些缓冲区进行具体的数据操作。
- TypedArray是JavaScript中的一组特定类型的数组,用于表示和操作二进制数据。它们允许直接操作内存中的原始二进制数据,而不需要通过复制或解释为字符串来访问。TypedArray包括以下几种类型:Int8Array(8 位带符号整数, -128 到 127)、Uint8Array(8 位无符号整数,0到255)、Int16Array(16 位带符号整数,-32768 到 32767)、Uint16Array(16 位无符号整数,0到65535)、Int32Array、Uint32Array(0到4294967295)、Float32Array( 32 位浮点数)、Float64Array等,分别用于表示不同类型的二进制数据。
上栗子:
1 | var buffer = new ArrayBuffer(5); |
上面的代码中,我们先是创建了一个固定长度为5个字节的ArrayBuffer对象。这个对象在内存中分配了一个连续的、固定大小的内存空间,用于存储二进制数据,通过创建一个Uint8Array对象来引用这个ArrayBuffer,以便操作二进制数据,最后,使用 set() 方法将包含数值的数组 [65, 66, 67, 1, 255] 复制到 Uint8Array 对象 bytes 中。这里的数值分别是 ASCII 字符 ‘A’, ‘B’, ‘C’ ,’╔’,’ÿ’的编码值,因为 Uint8Array 是按字节存储数据的,所以这里每个数组元素对应一个字节,依次填充了 ArrayBuffer 中的前五个字节,所以缓冲区中的内容现在是 [65, 66, 67, 1, 255],分别对应字符 ‘A’, ‘B’, ‘C’,’╔’,’ÿ。
需要注意的是8 位无符号整数刚好对应ASCII编码,如果超出这个范围,比如 889,js会取其模256的结果,即889 % 256 = 121,所以最终写入的值是121,对应的ASCII字符是’y’。
参考链接
 微信
微信 支付宝
支付宝