概要:在这篇记录中,我们将用 Venv 安装虚拟环境,并执行一个获取图片的爬虫代码,效果如下所示
安装virtualenv
创建虚拟环境
创建一个新的项目文件夹,在终端中使用 cd 切换到项目文件夹,并运行以下命令:
1
2
3
4
5
6
| python -m venv <virtual-environment-name>
// 比如
mkdir projectA
cd projectA
python -m venv my_env
|
我用的Windows成功后在文件夹下出现my_env文件夹,里面有Lib,Scripts等
激活你的虚拟环境,运行下面的代码:
成功的话会命令行前面会出现(环境名)前缀
关闭环境,输入以下命令即可:
vscode默认设置了,打开终端自动激活虚拟环境,可以在设置中搜索python.terminal.activateEnvironment,查看是否开启了这个配置
编写爬虫文件
我这里用的l站佬友分享的爬取头像的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
| import requests
from bs4 import BeautifulSoup
import os
import threading
def download_image(img_url, save_dir):
try:
img_data = requests.get(img_url, timeout=10).content
img_name = os.path.join(save_dir, img_url.split("/")[-1])
with open(img_name, "wb") as f:
f.write(img_data)
print(f"下载成功: {img_url} -> {img_name}")
except Exception as e:
print(f"下载失败: {img_url}, 错误信息: {e}")
def scrape_detail_page(detail_url, save_dir):
try:
print(f"正在爬取详情页: {detail_url}")
response = requests.get(detail_url, timeout=10)
if response.status_code != 200:
print(f"无法访问详情页: {detail_url}, 状态码: {response.status_code}")
return
soup = BeautifulSoup(response.content, "html.parser")
img_tags = soup.select("#content p img")
for img_tag in img_tags:
img_url = img_tag["src"]
download_image(img_url, save_dir)
except Exception as e:
print(f"爬取详情页失败: {detail_url}, 错误信息: {e}")
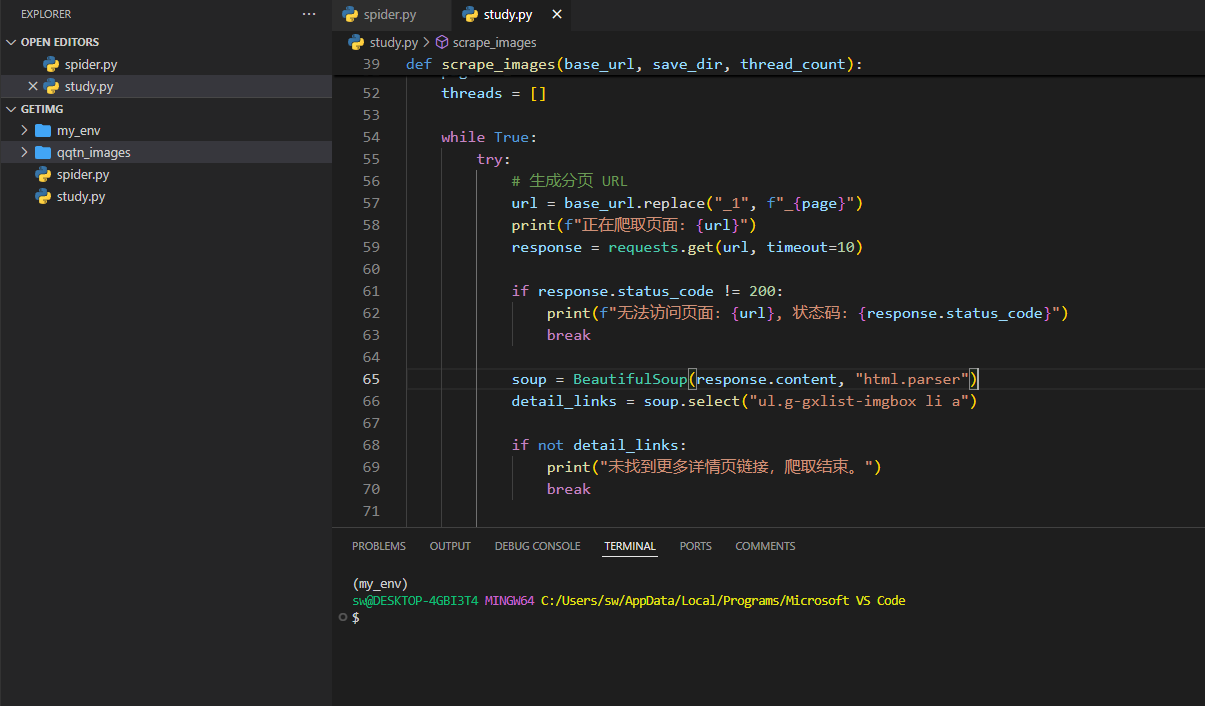
def scrape_images(base_url, save_dir, thread_count):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
page = 1
threads = []
while True:
try:
url = base_url.replace("_1", f"_{page}")
print(f"正在爬取页面: {url}")
response = requests.get(url, timeout=10)
if response.status_code != 200:
print(f"无法访问页面: {url}, 状态码: {response.status_code}")
break
soup = BeautifulSoup(response.content, "html.parser")
detail_links = soup.select("ul.g-gxlist-imgbox li a")
if not detail_links:
print("未找到更多详情页链接,爬取结束。")
break
for link in detail_links:
detail_url = "https://www.qqtn.com" + link["href"]
thread = threading.Thread(target=scrape_detail_page, args=(detail_url, save_dir))
threads.append(thread)
thread.start()
while len(threads) >= thread_count:
for t in threads:
t.join(0.1)
threads = [t for t in threads if t.is_alive()]
page += 1
except Exception as e:
print(f"爬取页面失败: {url}, 错误信息: {e}")
continue
for t in threads:
t.join()
base_url = "https://www.qqtn.com/tx/nvshengtx_1.html"
save_directory = "qqtn_images"
thread_count = 5
scrape_images(base_url, save_directory, thread_count)
|
文件名随意,后缀是py就行,需要放到根目录下,也就是和环境文件夹同级
执行爬虫
先确保命令行cd到保存 Python 文件的目录下,也就是根目录下,然后执行
退出的话,ctrl + c或者直接关闭程序
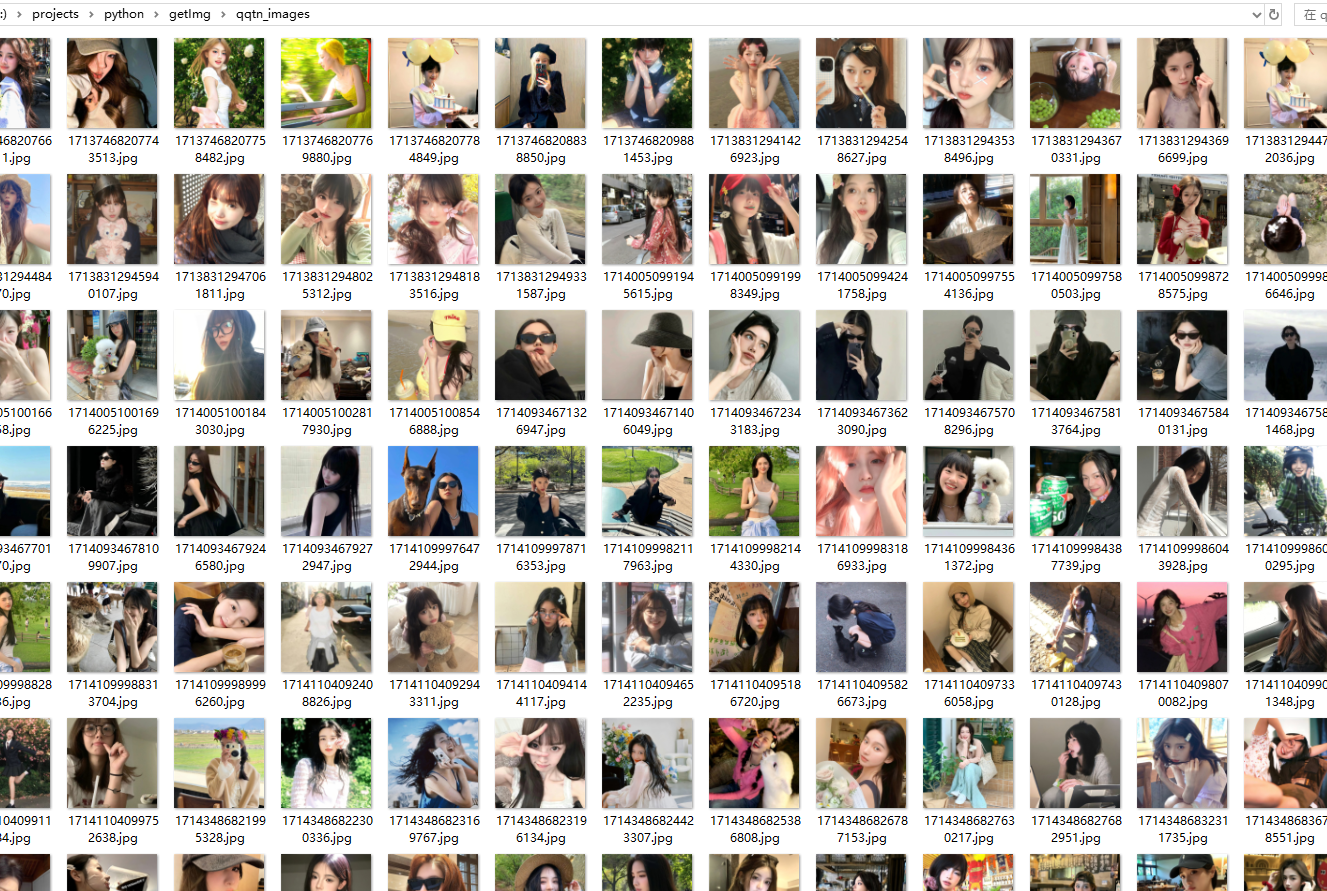
最终我们会在根目录下看到save_directory那传的目录名相同的文件夹,里面就包含了我们爬虫后得到的所有头像
疑问解答
1.Python 中的JSDoc 注释
1
2
3
4
5
6
7
8
9
10
11
| def add(x, y):
"""Adds two numbers.
Args:
x: The first number.
y: The second number.
Returns:
The sum of x and y.
"""
return x + y
|
文档字符串是放在函数、类或模块定义的第一行的一个字符串,用三个引号 (‘’’ 或 “”” ) 括起来。
参考链接
linuxDo
 微信
微信 支付宝
支付宝